論文生成モデルの検討を通して論文執筆を進めてみる
今期の論文執筆に着手しながら相変わらず上手く書けていなかったのだけれども,自分をある論文生成モデルの実行基盤だと考えると歯車が回り出した気がしたので書いておく.
今回考えた論文生成モデルはこんな感じ.
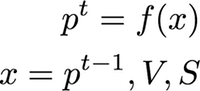
ここで,p^tは入力xに対して出力されるt時点の論文内容である.入力xはt-1時点の論文とV(バリュー.研究成果),S(サーベイ)とする.
なお,fはGANのようなDiscriminatorとGeneratorを持つ生成モデルであり,実行基盤の特性上,Generatorは常にDiscriminatorよりも低精度である.
実際は執筆,推敲を意識して役割分担しながら短いサイクルで繰り返すだけではあるが,以下のように執筆行為を捉えることで執筆時の心理的負担を減らすようにしている.
以下,本モデルの詳細と利点について述べる.
従来の執筆時は二つの役割を同時に実行していた
基本的に論文執筆は難しいものだと思う.昨年の振り返りで先行研究の理解と再構成の必要性を痛感し,サーベイなどに努めているが,いざ書き出すとなると上手く書けない.考えはあるし,簡単なメモ書きや口頭なら出力することができるのに,論文として書こうとすると筆が止まる. 筆が止まる時は大抵,自分の中で批判者がいて,内容を書き出す前にダメ出ししている感じである.つまり,執筆という行為において,自分の中に執筆者と批評者の二つの役割がいると考えられる.この辺りはノンストップライティングで言うところの反省的思考の除去という捉え方に通じるものもある.しかしながら,論文執筆においてはその批評的な視点も思考をねりあげるのに必要なステップであり,これを除去してしまってはいけない. 問題はこれらの役割を脳内で分離せず,かつ同時に実行していることであり,これらの役割が別であることを認識した上で,GAN的に別々の担当者が交互に役割を遂行することが,書き出しを阻害せず,かつ論文としての精度向上も図れるのではないかと考える.
出力と判断に対する認知的負荷の差
一般に,人間はある概念を言語化するよりも,すでに表現されたものが概念に合致するかどうかを判断する方が認知的負荷が低くなる.そのため,情報推薦の分野では情報探索プロセスにおいて都度適切な検索クエリを表現してもらうよりも結果から取捨選択してもらうことでフィードバックを得るような手法もある.文章を書き出すよりも,その良さを判断する方が容易なのはこのような特性があるからである. 逆に言えば,読むときのレベルではそうそう書けないのであり,そのように納得してしまえば,思ったより練度の低い文章が出力されるても落ち込まずに許容できるようになる.重要なのはまずGenerateして,次のDiscriminatorに渡すことである.
提案手法を意識した論文執筆の利点
上記のように論文執筆を弱い執筆者と強い推敲者とに役割分担しながら進めることで以下の利点がある.
- サーベイや研究成果などの入力が変化しない状態においては,地道に執筆を繰り返すしかない.逆に言えば何か書けば進むという状態が開ける.
- GeneratorとDiscriminatorの工程が分離されていることでGenerate時の心理的な負担が減る
- Generatorの精度が低いのはそういうものだと割り切れるのでGenerate時の心理的な負担が減る
どれだけ執筆時に心理的な負担を減らすかが自分の中では大事なようだ.
実際には教師データがないのでGANとは言えないのだけれども,役割を明確に分離することで出力精度を向上させていくというアプローチを参考にした.少なくともここ最近は執筆は何かしら進んでいて,内容は幸いにして自分の中のDiscriminatorが頑張ってくれているので少しづつは良くなっていると思う.混沌とした文章がなんだか論文らしきものになっていく様はまさに生成モデルのようであり,よりよくするためにステップを継続することが楽しみにすらなってくる.
自分の中で色々がんじがらめになってしまって動けない人は,このように行為を解釈することでまずは進み出してみてはいかがだろうか.