Sanny: 大規模ECサイトのための精度と速度を両立した分散可能な近似近傍探索エンジン
このエントリは、第二回 Web System Architecture 研究会 (WSA研)の予稿です。
はじめに
ECサイトの商品種類増大に伴う情報過多問題を解決するため,利用者の要求を満たす商品を自動的に提案する機能がECサイトにとっての関心事となる.商品の提案は任意の観点での商品同士の類似性を根拠とすることから,商品の特性を数値化し,任意の距離空間で近傍に位置する要素を求めることで,機械的に扱えるようにする.この数値化された商品特性を特徴量と呼ぶ. 深層ニューラルネットワークの発展によって,これまで適切な特徴量を導くことが難しかった画像やテキストに対しても,人の感性に近い,特性をよく表現する高精度な特徴量を得られるようになったことからECサイトの商品提案機能に利用され始めている. これらの深層ニューラルネットワークから得られる特徴量は,数百から数千次元の高次元ベクトルとして表現される. また,大規模なECサイトでは提案対象となる商品数も多いため,この特徴量の集合も数十から数百万を超える大規模なものとなる. このような大規模かつ高次元ベクトル集合に対する類似度の比較において,正確ではあるが,データ数と次元数に比例して計算量が増加する線形探索は現実的ではない.そこで,事前に近傍候補となる集団を求めておくことで,少数の近傍候補から計算量を抑えて近傍点を得る空間分割や局所性鋭敏型ハッシュといった手法が用いられる. しかしながら,高次元ベクトル集合においては正確な近傍を求めるための計算量が線形探索と同程度となると考えられており,精度を犠牲にして近似解を用いることで計算量の増加に対処する近似近傍探索が採用されているが,商品を自動的に提案する機能は、提案内容の的確さと充分な応答速度が求められることから,大規模かつ高次元ベクトル集合に対して精度と速度を両立する近似近傍探索の手法が必要となる.
大規模かつ高次元ベクトル集合に対する近似近傍探索では,データ数と次元数に依存して計算量が増加するため,これらを分割して処理することが効果的である. ベクトル集合を行列と見なし,行方向での分割,つまりデータ数によって分割する手法は一般に採用されるが,依然として次元数に依存した計算量の課題は残る. そこで,列方向での分割が必要となる. 直積量子化は,高次元ベクトル集合を任意の次元数の低次元ベクトル集合に等分し,各低次元ベクトル集合に対する近傍探索結果を集約する. しかしながら,集約処理はデータ数に依存するという課題がある.
そこで,本報告では,大規模ECサイトで商品を提案することを想定して,精度と速度を両立した分散可能な近似近傍探索エンジンSannyを提案する. Sannyは,商品特性をよく表現しており高精度に類似度が比較可能な高次元かつ密なベクトルの集合において,検索質問データ(クエリ)に対する高次元ベクトル集合の近傍探索結果の上位集合が,クエリと高次元ベクトル集合を任意の次元数で等分した部分ベクトル単位で近傍探索した結果の上位集合と類似しやすいことに着目して,提案すべき商品の近傍探索を部分ベクトル単位での探索に分解することで分散処理可能にし,その探索結果の和集合である近傍候補から再度近傍探索を行うことにより,全体として高速に近似近傍探索を行える.
提案手法
事前準備
提案手法ではまず,商品特性をよく表現しており高精度に類似度が比較可能な高次元かつ密なベクトルの集合を対象とする. このような集合として,学習済み深層畳み込みニューラルネットワークを特徴抽出器として利用して画像から得られる特徴量集合や,テキストを分散表現へ変換するWord2vecのネットワークから得られる特徴量集合がある. 筆者らはこれらの集合において,検索質問データ(クエリ)に対する高次元ベクトル集合の近傍探索結果の上位集合が,クエリと高次元ベクトル集合を任意の次元数で等分した部分ベクトル単位で近傍探索した結果の上位集合と類似しやすい特性があることを見出した. この,高次元ベクトルで表現される特徴量のうち,部分が類似しているものは全体としても類似する可能性が高いという特性を利用することで,高次元ベクトル集合を列方向に分割した結果の集約のデータ数依存の課題を解決する.
ここでは,対象となるベクトル集合を$Y \subset \mathbb{R}^D$と置き,これを重複しない$D^*=D/m$次元の部分ベクトル$S_j(1 \leq j \leq m)$に分割する.
近傍探索
Yに対する近傍探索は次のように行う. クエリベクトル$q \in \mathbb{R}^D$を$p_j (1 \leq j \leq m)$に分割し,対応する添え字$j$の部分ベクトル集合$s_j$に対して上位$n$件を得る近傍探索を行う.
\begin{align} NN(p_j) = \argmin_{s \in S_j} d(p_j,s) \end{align}
$NN(p_j)$の結果を$n$個の識別子からなる集合$N_j$とし,全ての$N_j$の和集合を$N$としてこれを近傍候補とする.なお,距離関数には現時点でユークリッド距離を想定しているが,すべての部分ベクトルで統一されていれば近傍探索の手法自体は問わない.
最後に近傍候補$N$に対応する元のベクトル集合 $YN \subset \mathbb{R}^D$ に対して正確な類似度を比較するためにクエリベクトル$q$との線形探索を行う.$|YN|$は最大$n*m$であることから線形探索のコストは非常に小さいが,距離関数にユークリッド距離を用いる場合,以下で求まる近似的な線形探索を用いることで一層の高速化が見込める.
\begin{align} argmin_a (a - b)^2 = argmin_a a^2 - 2ab + b^2 = argmin_a a^2 - 2ab \end{align}
システム構成
提案手法では,探索対象となる高次元ベクトル集合を任意の次元数で等分した部分ベクトルに分割する.これらの部分ベクトルに対する近傍探索は互いに独立していることから並列に処理することができるため,データ数や次元数に応じた分散構成を取ることができる. 分散構成では,部分ベクトルの近傍探索結果$N_j$がネットワーク上でやり取りされるが,前述のように最小限のデータ量のみが通信されることからネットワーク通信における影響を抑えることができる.なお,大規模なECサイトにおいては大量のクエリが想定されることから,HTTP/2のバイナリフレームレイヤーのように通信の多重化を行うことで影響を抑える手法も合わせて導入する.
また,分散構成では,データを重複して保持することで,可用性も高めることができる.
評価
速度と精度による性能評価
以下に,2048次元,40,000件程度の高次元ベクトル集合に対して提案手法と従来手法の精度と速度のバランスを比較した予備実験の結果を示す.横軸は再現率であり,各手法の提示した予測近傍集合と正しい近傍集合との重複率である.縦軸は検索にかかった秒数の逆数を取ったもので,上にあるほど高速である. 従来手法として,線形探索(brute_force),近似線形探索(brute_force_blas),近似近傍探索(annoy)と比較した.提案手法は,近傍候補から正確な近傍を求めるために用いた手法ごとに評価を行なっている.
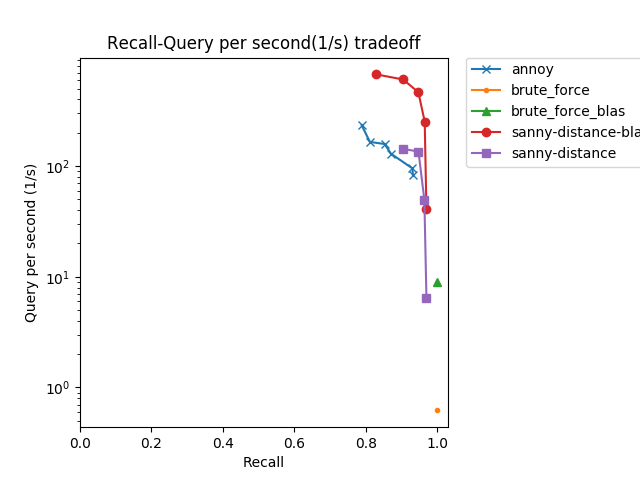
結果から,近傍候補からの探索に近似線形探索を用いた場合の提案手法が従来の近似近傍探索手法より精度並びに速度でも有効であることを示している.
発表スライド
発表を終えて
大規模なデータセットでの評価,事前分類による推薦との差など研究報告としてはまだ新規性や有用性の面で示しきれていない箇所もあったが,そこも含めて議論ができてよかったと思う.特にGPU環境での評価や,データ数や次元数への依存が少ないと思われるLSHなどの手法への適用など具体的に差を示すべき箇所が浮かんできたのが収穫である.サーベイ並びに評価を進めたい.
WSA研は,事業で研究的なアプローチをどう活かすかを普段から考えて実際に成果を出している人々が集まっている.研究成果とサーベイを携えて次はどう論述するかについて吸収し,次回は誰かに影響を与えられるようになれたら良いなと思う.