The Platinum Searcherを5倍高速化するためにやったこと
この記事は Go Advent Calendar 2015 その2 の 15日目の記事です。
先日、5倍の高速化を実現した高速検索ツールThe Platinum SearcherのV2をリリースしました。
今回は、高速化にあたり工夫した点をまとめておこうと思います。
The Platinum Searcherの基本実装について
以前、GoConferenceで発表した資料にまとめてあるので、興味のあるかたはご覧ください。 基本的にはFind、Grep、PrintのGoroutineがそれぞれの結果をChannelを経由して渡すつくりになっており、それぞれのGoroutine内で並行で処理を行うために更にGoroutineを起動しています。
ボトルネックの調査
今回は完全書き直しだったのでボトルネックを潰していくという手法ではなかったのですが、再実装にあたり、気をつけるべき点を確認する上でも現状のボトルネック箇所を最初に調査しました。
プロファイリングツールにはpprofを使います。既存のコードに以下を追加し
cpuprofile := "mycpu.prof"
f, _ := os.Create(cpuprofile)
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
ビルドして、処理(今回は検索)を実行、出力された結果に対して top や top20 などを使いボトルネックを確認します。
$ go build -o pt cmd/pt/main.go
$ ./pt EXPORT_SYMBOL_GPL ~/src/github.com/torvalds/linux/ > /dev/null
$ go tool pprof pt mycpu.prof
Entering interactive mode (type "help" for commands)
(pprof) top
16.02s of 16.59s total (96.56%)
Dropped 102 nodes (cum <= 0.08s)
Showing top 10 nodes out of 85 (cum >= 0.16s)
flat flat% sum% cum cum%
14.67s 88.43% 88.43% 14.67s 88.43% syscall.Syscall
0.70s 4.22% 92.65% 0.70s 4.22% nanotime
0.15s 0.9% 93.55% 0.15s 0.9% runtime.mach_semaphore_timedwait
0.13s 0.78% 94.33% 0.13s 0.78% runtime.mach_semaphore_wait
0.12s 0.72% 95.06% 0.12s 0.72% runtime.memmove
0.11s 0.66% 95.72% 0.11s 0.66% syscall.Syscall6
0.10s 0.6% 96.32% 0.10s 0.6% runtime.usleep
0.02s 0.12% 96.44% 0.19s 1.15% runtime.findrunnable
0.01s 0.06% 96.50% 7.08s 42.68% bufio.(*Reader).ReadLine
0.01s 0.06% 96.56% 0.16s 0.96% github.com/monochromegane/the_platinum_searcher.patterns.match
(pprof)
syscall.Syscallが一番時間がかかっていることは分かりますが、どこから呼ばれたものかをさっと把握は難しいです。
こういう場合は web を使うことで呼び出し元含めて図示することができます。 全体図はこちら
{kind=link}
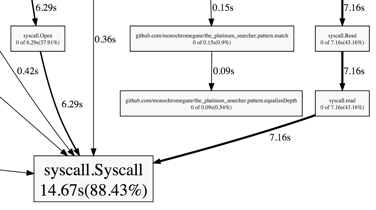
全体図から syscall.Read と syscall.Open が時間がかかっており、それぞれの呼び出し元が Grep時のbufio.ReadLine と Find時の os.Open であることが判明したのでV2ではこれらに注意しながら再実装を進めることにしました。
Findの高速化
Findは対象のディレクトリを探索し、gitignore対象を除外した上で、Grepに対象ファイルパスを渡していくのが仕事です。当然、Grepのほうがファイルの読み込みと文字列検索処理が入り、遅くなるのですが、Findが遅いと、主に立ち上がり時にGrepが暇をしてしまうので、ここもある程度高速であることが求められます。
V1系の実装では、デフォルトで検索対象のディレクトリ直下のディレクトリ数分だけGoroutineを起動していましたが、V2では上限値までは常にGoroutineを起動してFindの多重度を高めています。
Find時のGoroutine起動部分はこのようになっています。
wg := &sync.WaitGroup{}
for _, file := range files {
f := newFileInfo(path, file)
select {
// 同時起動可能であればGoroutineを使う
case sem <- struct{}{}:
wg.Add(1)
go func(path string, file fileInfo, depth int, ignores ignoreMatchers, wg *sync.WaitGroup) {
defer wg.Done()
defer func() { <-sem }()
walk(path, file, depth, ignores, walkFn, sem)
}(filepath.Join(path, file.Name()), f, depth, ignores, wg)
// 同時起動数の上限に達していれば通常のwalk
default:
walk(filepath.Join(path, file.Name()), f, depth, ignores, walkFn, sem)
}
}
wg.Wait()
ここでは、よくある同時起動数の制御を行っていますが、selectを使って同時起動可能でなければGoroutineを使わずに処理を継続するという方法をとっています。
Grepの高速化
受け取ったファイルを読み込み、パターンにマッチする文字列を探す部分です。また、文字コードの判定も行います。
V1系では素直に1行読んで、パターンにマッチするかどうか判定するという実装で、さらに文字コード判定時に別途同じファイル読み込みを行っていました。これは実装が簡単な反面、IOが多く発生してしまいます。
IOの削減
V2系ではこれを見直し、大きめのバッファを用意して読み込み、その中でパターンにマッチするものがあるか、文字コードがなんであるかを判断するようにしてIO(syscall.Read)を減らしています。
// bufferを確保
buf := make([]byte, 8196)
for {
// 読み込み
c, err := f.Read(buf)
if err != nil && err != io.EOF {
log.Fatalf("read: %s\n", err)
}
if err == io.EOF {
break
}
// 文字コードの判定
if !identified {
limit := c
if limit > 512 {
limit = 512
}
encoding = detectEncoding(buf[:limit])
...
}
// bufferにパターンが含まれるか判定
if bytes.Contains(buf[:c], pattern) {
...
固定サイズのバッファだと行の途中で切れてしまう箇所がありますが、途中で切れた部分は一度退避しておいて、次の読み込んだバッファと結合して欠損をリカバリするような処理を書いています。
文字コード変換コストの削減
EUCやShiftJISのファイルを検索する際にV1ではファイル側の文字コードをUTF-8に変換して判定していましたが、V2からはパターン文字列側を文字コード変換してファイル側の文字コード変換のコストを削減しています。
パターンにマッチしたファイルの処理
実際はパターンにマッチしたファイルについては行単位でマッチする行を再度探しなおします。これは処理の共通化やPrintまわりの実装を複雑にしないためですが、Grepはマッチするファイルかどうかの判定が一番多く、ここに対しての最適化をまず行ったためです。今後、まだ高速化したい場合はここも含めてチューニングを検討していこうと思っています。
Printの高速化
Grepで見つかった文字列を画面に表示する処理です。ファイル単位でグルーピングした結果を出力する必要があるため、出力を排他する必要があります。
排他処理
V1系では排他処理のためbufferが1のchannelを設け、Print用のGoroutineを起動していましたが、V2ではsync.Mutexを使った排他処理に変更しました。
func (p printer) print(match match) {
p.mu.Lock()
defer p.mu.Unlock()
if match.size() == 0 {
return
}
p.formatter.print(match)
}
ここのベンチマークはnaoinaさんのGolang パフォーマンスチューニング - 例えば、channel を使わないなどが参考になると思います。
文字列結合を減らす
また、微々たるものですが、様々な出力形式に対応するため細かい単位でfmt.Printfを使っていた(1行内で複数回使うこともあった)のをできるだけfmt.Printfを使わない、文字列結合をまとめるなどを行っています。
Gitignore
The Platinum SearcherではGitignoreの判定を自前で実装しています。V1系では素直に全パターンをマッチングしていましたが、パターン数が多い場合にボトルネックとなり得る状態でした。
マッチング対象のパターンを減らす
V2系ではマッチング対象のパターンを少なくするために以下のようなシンプルな(原始的な)木構造のインデックスを用意するようにしました。
.
├── accept # 許可リスト(e.g. !hoge)
│ ├── absolute # 絶対パス
│ │ └── depth # 階層数
│ │ ├── initial # 頭文字[a-zA-z0-9]
│ │ └── other # その他の頭文字
│ └── relative
│ └── depth
│ ├── initial
│ └── other
└── ignore # 無視リスト
├── absolute
│ └── depth
│ ├── initial
│ └── other
└── relative
└── depth
├── initial
└── other
depthはパターンの階層数で、initialはパターンの頭文字です。渡されたファイルパスから必要なパターンのみを取り出して最小限のマッチングを行います。
木構造の末端に含まれるパターン数は必ずしも均等にはならないですが、単純に全パターンのマッチよりは充分高速に判定可能になりました。
以下65個のパターンが含まれるlinuxカーネルのgitignoreに対してのマッチングをベンチマークしたものです。
BenchmarkIndex-4 3000000 397 ns/op 0 B/op 0 allocs/op
BenchmarkFull-4 200000 5896 ns/op 0 B/op 0 allocs/op
go-gitignore
また、こちらの高速なgitignore判定については、パッケージに切り出したのでもしGitignore判定したいというニッチなニーズをお持ちの方は使ってみてください。
Channel bufferのチューニング
The Platinum SearcherはFindの同時起動数、Grepの同時起動数、FindとGrepをつなぐChannelのBuffer数が主に性能に影響してくるパラメタとなります。
これらのチューニングですが、今回は実際の値を見ながら数値を変更して最適な値を探っていくというだいぶ泥臭いやり方になりました。何かよい方法があれば教えて下さい。
// GoroutineとChannel bufferの利用数を出力する
go func() {
for {
time.Sleep(10 * time.Millisecond)
fmt.Printf("NumGoroutine %d / NumBuffer %d\n", runtime.NumGoroutine(), len(grepChan))
}
}()
Findの同時起動数はFind単体で実行した際はもう少し増やすことで性能出るのですが、Grepのほうにリソースが行き渡らなくなるためか、全体としては増やし過ぎると遅くなるという結果になりました。
またGrepについても同様ですが、OS側のキャッシュが効いていない場合、ファイルを閉じる処理が間に合わずに too many open files が発生してしまうため現状の値にしています。
GOMAXPROCSについて
GOMAXPROCSはCPUコア数以上を指定しても現状のThe Platinum Searcherの構成では速くはならずむしろ若干遅くなるという結果になりました。IO待ちなどが発生する間、他にやる処理があるようなプログラムの場合は、CPU数以上増やしても効果があるかもしれませんが、runtime.NumCPU()と同じ(1.5からのデフォルト)が一番バランスがよさそうです。
func init() {
if cpu := runtime.NumCPU(); cpu == 1 {
runtime.GOMAXPROCS(2)
} else {
runtime.GOMAXPROCS(cpu)
}
}
まとめ
The Platinum Searcherの高速化について代表的な修正を書き出してみました。単純にGoroutine使ったらこんなに速い〜からもう少し踏み込んだチューニングが今回出来たのではないかなと思います。
また、今回の高速化はあくまでThe Platinum Searcherで効果があったことであり、上記のことをやれば必ず速くなるわけではないと思います。実際、ミニマムな実装をつくって何か処理を実装する度に処理時間を計測し、パラメタの調整や使う関数のベンチマークをとって処理時間の少ない方、アロケートの少ない方を採用するよう地道に実装を進めました。遅いと言われている処理を使っても使いドコロによっては影響なかったり、逆に意外なところが遅くなったりもします。
まさに 推測するな、計測せよ ですね。
最後にV1とV2の差分とプロファイリング結果をおいておきます。なにかの参考になればうれしいです。
{kind=link}
明日は Go Advent Calendar 2015 その2 の 16日目です。担当はhogedigoさんです。